








Nvidia、AMD和Intel罕见联手,投资一家光芯片公司
- 暴富
- 2024-12-12 13:42:05
- 61
来源:华尔街见闻
这家名为Ayar Labs的光芯片初创公司,致力于打破过去的数据传输模式,目标是将光通信直接置于封装上,而不是受到IO密度问题、数据速率扩展和电子封装到封装互连的功率低效性限制。
近年来,随着AI竞争愈演愈烈,无论是传统还是新兴的处理器巨头都在围绕CPU、GPU和AI加速器展开了激烈竞争。尤其是AMD、Intel和英伟达三大标志性巨头,由于三者的竞争包含后来者的追赶逆袭、新市场的来势汹汹、老巨头的不甘人后等情节,使得这三个巨头的任何动向尤为关注。这三家公司围绕着人工智能和PC展开明争暗斗也是众所周知。
但近日,这三家公司罕见联手,投资了一家名为Ayar Labs的光芯片初创公司。
三大芯片巨头,看上光互连
Ayar Labs今天宣布,已获得由 Advent Global Opportunities 和 Light Street Capital 领投的 1.55 亿美元融资,旨在利用其光学 I/O 技术打破 AI 数据移动瓶颈。这使该公司的总融资额达到 3.7 亿美元,并将公司估值提高至 10 亿美元以上。
正如Ayar Labs所说,本轮融资的规模和投资者的素质标志着 Ayar Labs 的又一个重要里程碑,该公司正在准备其光学解决方案,以战略性地配合客户路线图进行大批量生产。该公司表示,参与本轮融资的知名公司就涵括了当前最炙手可热的芯片三大巨头AMD Ventures、Intel Capital 和 NVIDIA ,其他新战略和金融投资者包括 3M Ventures 和 Autopilot。值得一提的是,在之前,Ayar Labs也拿了包括Applied Ventures LLC、Axial Partners、Boardman Bay Capital Management、GlobalFoundries、IAG Capital Partners、Lockheed Martin Ventures、Playground Global 和 VentureTech Alliance在内的众多知名企业和机构的钱。
Ayar Labs 首席执行官兼联合创始人 Mark Wade 表示:“领先的 GPU 提供商 AMD 和 NVIDIA 以及半导体代工厂 GlobalFoundries、Intel Foundry 和 TSMC,再加上 Advent、Light Street 和我们其他投资者的支持,凸显了我们的光学 I/O 技术重新定义 AI 基础设施未来的潜力。”“我们非常幸运,在这轮融资中,Light Street 在技术特定投资方面的深厚专业知识以及 Advent 强大的私募和成长股权背景为我们提供了支持。”
据相关资料显示,Ayar Labs成立于 2015 年,公司团队由来自英特尔、IBM、美光、Penguin、麻省理工学院、伯克利和斯坦福的许多顶尖技术专家组成。
在官网的介绍中,Ayar Labs将公司定位为光学互连解决方案领域的领导者,其提供的产品数据传输速度与 AI 相当。公司表示,在意识到 AI 模型的复杂性和规模正在以传统互连技术无法处理的速度增长,他们开发了业界首个光学 I/O 解决方案,使客户能够最大限度地提高不断增长的 AI 基础设施的计算效率和性能,同时降低成本、延迟和功耗。Ayar Labs指出,公司的光学 I/O 解决方案基于开放标准,并针对 AI 训练和推理进行了优化,拥有强大的生态系统,使其能够顺利大规模集成到 AI 系统中。

如上图所示,Ayar Labs 表示,公司故事的起源可以追溯到公司在2010年的发布的一篇名为《Open foundry platform for high-performance electronic-photonic integration》的论文。据介绍,该文章论述采用当时商用电子 45 nm SOI-CMOS 代工工艺制造的具有 3 dB/cm 波导损耗的光子器件。通过利用现有的前端制造工艺,光子器件与电子器件单片集成在与晶体管相同的物理器件层中,实现 4 ps 逻辑级延迟,而不会降低晶体管性能。
在文章中,他们展示了一个 8 通道光学微环谐振器滤波器组和光调制器,它们均由集成数字电路控制。通过开发一种不需要任何工艺基础设施更改的器件设计方法,可以实现广泛可用的高性能光子电子集成电路平台。
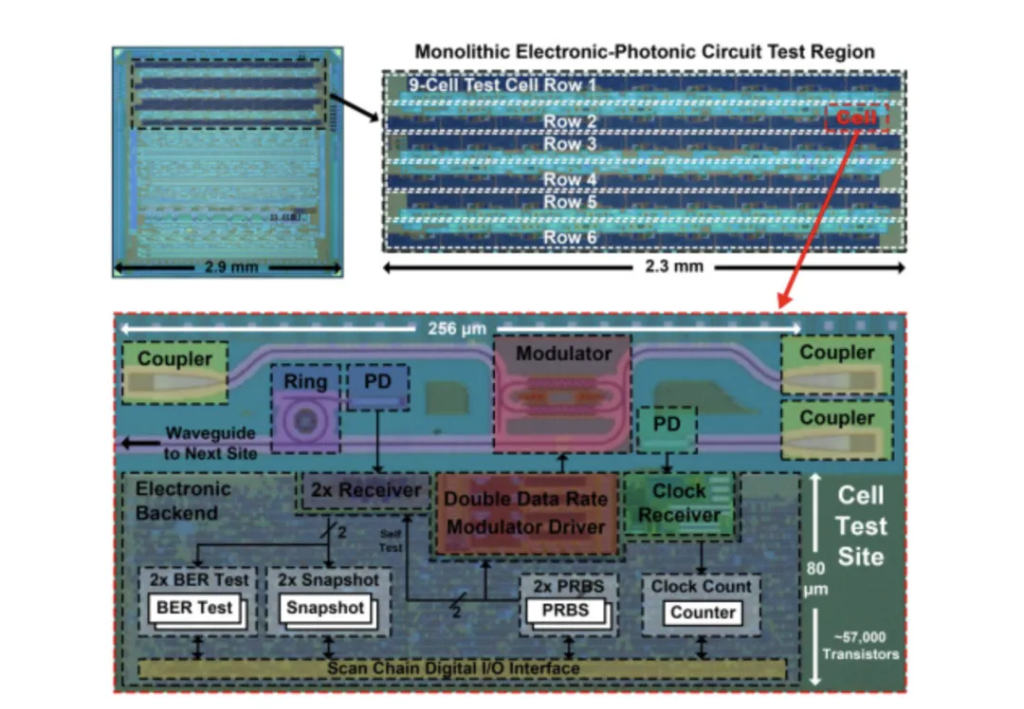
在文章的论述阶段他们强调,论战展示的电子-光子平台是一种可访问的、低成本的利用现有电子代工厂基础设施的方法,可用于制造高性能光子器件和最先进的 CMOS 晶体管。使用薄 SOI-CMOS 工艺无需进行代工厂内部改动,只需进行简单的后处理即可实现良好的无源光子性能,消除了之前工作中存在的波导损耗瓶颈。文章介绍的滤波器组解复用器和调制器等设备,以及目前正在开发的集成光电探测器,构成了先进电子工艺中光子互连平台的基础,该工艺可用于制造当今的微处理器。该代工平台的通用性质使我们可以使用最先进的技术,这将极大地促进整个 VLSI 和光子系统及应用领域的新型电光片上系统的研究。
正是基于这个研究,Ayar Labs在2015年宣告成立,然后在次年获得了种子轮投资(GlobalFoundries 参与了种子轮融资)。
Ayar Labs,聚焦解决的问题
在具体介绍Ayar Labs的产品之前,我们先介绍一下他们具体想解决什么问题。
正如之前很多报道中所说,高性能计算引擎存在带宽和信号问题,这已经不是什么秘密了。如果你想要以合理的每秒容量快速地将数据输入和输出,从而让引擎中的数十到数万个核心保持忙碌,那么如果你要坚持使用铜线,就必须尽可能紧密地连接它们,无论是插入堆叠内存的插入器上的走线,还是进出 SerDes 的电线,以将计算引擎连接在一起以并行运行。
问题在于电线的长度过长。每次将带宽增加一倍时,由于信号失真,您都必须将电线长度减半。这是物理学和材料科学的问题,每个人都知道最终铜线将被光纤取代。而且由于人工智能工作负载对带宽的巨大需求,未来几年内这似乎将真正成为不可避免的趋势。
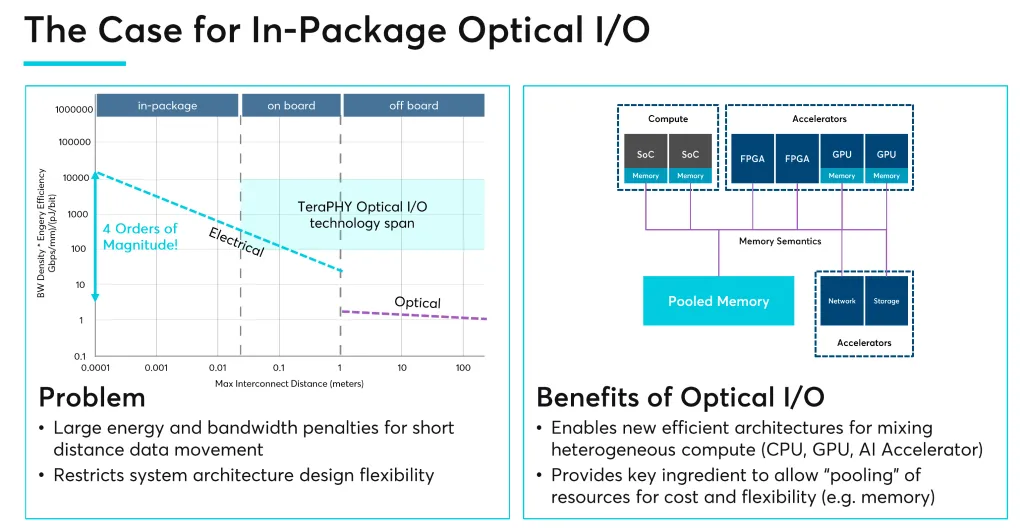
Ayar Labs也正是这样的“光”参与者,致力于打破过去的数据传输模式。
据了解,他们的目标是将光通信直接置于封装上,而不是受到 IO 密度问题、数据速率扩展和电子封装到封装互连的功率低效性限制。Ayar Labs 的主要观点是,在 1cm 到 10cm 的传输范围内,光学 IO 比当前的电子系统更高效。解决数据传输功率膨胀问题的最佳方法是,只要您将数据传输到此距离以外,就切换到光学。
知名行业分析机构semianalysis表示,转向共封装光学器件有许多好处。例如数据不需要从处理器发送到网卡,也不需要通过昂贵的光收发器。处理器本身也可以节省大量成本,因为不必将太多的芯片面积专用于大型高速电气 SerDes。
鉴于 Ayar Labs 已加入开放的 UCIe 标准,Semianalysis认为他们的芯片将使用该协议作为与外部公司芯片接口的基础层。UCIe 支持英特尔、ASE 和台积电的许多封装选项。在处理器方面,英特尔、AMD、博通、美光、联发科和 GUC 都是该联盟的成员。UCIe 极大地降低了将第三方芯片集成到封装中的进入门槛,这反过来应该会降低 Ayar Labs 获得设计胜利的进入门槛。此外,Ayar Labs 也明确支持高密度扇出、英特尔的 EMIB 和其他硅中介层技术。
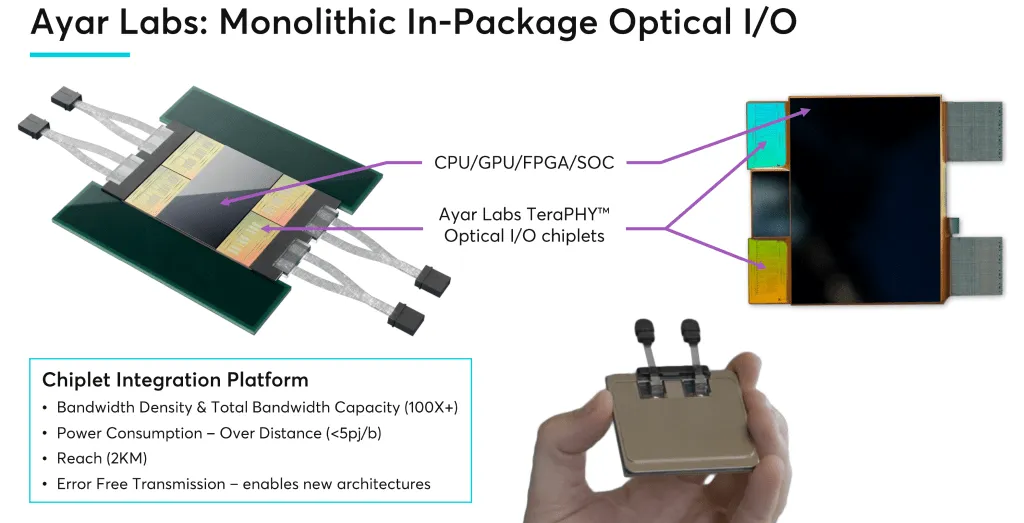
目前,Ayar Labs有两种主要的产品:一是SuperNova 光源——这是封装外部的远程光源,可以将其视为位于 ASIC 封装外部某处的光电源;另一个是TeraPHY 光学 I/O 芯片,这种硅片包含约 7000 万个晶体管和 10,000 多个光学器件。据介绍,他们将硅光子器件集成到 CMOS 工艺中,制成我们作为芯片出售的硅片。该芯片集成到客户 SOC 封装中。

从官网可以看到,SuperNova远程光源是 Ayar Labs 光学 I/O 解决方案的支柱,也是业界首款符合 CW-WDM MSA 标准的 16 波长光源,可提供多达 16 种波长的光并为多达 16 个端口供电。与 Ayar Labs TeraPHY 光学 I/O 芯片组相结合,与传统互连(可插拔光学器件 + 电气 SerDes)相比,该解决方案可提供 5 至 10 倍的更高带宽、10 倍的更低延迟和 4 至 8 倍的更高能效。光学 I/O 消除了 I/O 瓶颈,超越了工艺限制,并为下一代 AI 架构释放了创新架构。

TeraPHY光学 I/O 芯片组则是一种体积小、功耗低、吞吐量高的铜背板和可插拔光学通信替代方案。TeraPHY 芯片组的模块化多端口设计可承载八个光通道(相当于 x8 PCIe Gen5 链路)。这款业界首创的光学 I/O 芯片组将硅光子学与标准 CMOS 制造工艺相结合。它适用于现有的系统级封装架构,不需要 SoC 定制。
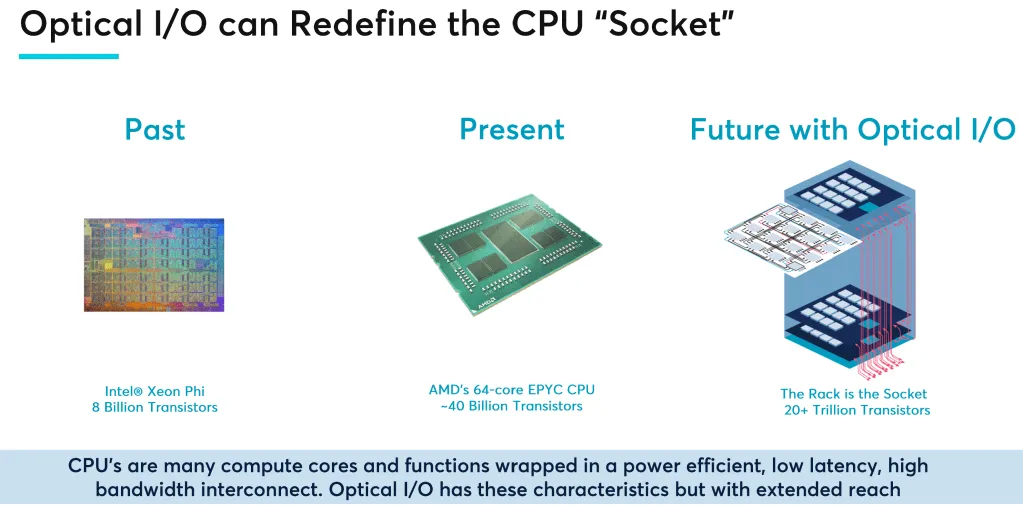
按照该公司CEO Mark Wade所说,Ayar Labs目前的主要商业模式是销售实际产品。他表示,SOC领域已经发生了整个范式转变,以推动 chiplet 的采用。如果你打开 ASIC 的盖子,你会看到里面有多个芯片。于是,Ayar Labs将所谓的“KGD”光学芯片装入客户的封装中销售。来到光学 I/O 芯片方面,Ayar Labs将其作为创收产品销售,客户只需直接从我们这里购买芯片即可。
Wade强调,Ayar Labs的市场策略专注于解决光子学领域的大批量、高质量制造问题。我们与 GlobalFoundries、Applied Materials、英特尔和台积电等主要公司建立了战略合作关系,并与所有一线 CMOS 制造商展开合作。
Ayar Labs还与大型 AI 系统领域的领导者 Nvidia 建立了战略合作伙伴关系,共同将我们的技术融入未来的 AI 系统。公司的直接客户正在构建 SOC 和 SOC 系统,其一流生态系统包括 Nvidia、AMD、英特尔、博通和高通等公司。
“构建大规模 AI 模型的终端客户(例如 Anthropic 和 OpenAI)至关重要。数据中心在尝试扩展 AI 工作负载时出现了许多严重问题。我们发现,这些公司对未来的愿景与我们多年来的预测相似,这证实了这一点。”Ayar Labs CEO Mark Wade强调。“我们的成功取决于能否进入这些领域。我们正在应对光子技术方面的挑战,特别是在大批量、高质量制造方面。这种方法使我们能够与行业主要参与者合作,同时满足最终用户的需求,从而突破人工智能技术的界限。”Mark Wade接着说。
Ayar Labs 今年八月曾表示,将发布其光学 I/O 技术来取代芯片内的铜线。该公司正在开发将光学 I/O 放入芯片结构中的技术,并已研究该技术十多年。该技术允许芯片内部实现更快的通信,旨在取代速度较慢的铜线。
“借助光学 I/O,你可以突破几十米甚至几百米的距离,然后连接更多的 GPU 或加速器,”Wade 说。
大规模商用在即?
在人们很容易认为,Nvidia、AMD 和英特尔的投资预示着这些公司正在寻求以某种方式在其计算引擎中部署 TeraPHY 光学传输及其 SuperNova 激光源。我们知道,他们的早期投资者HPE早在 2022 年 2 月就与 Ayar Labs 达成了一项战略投资和合作协议,将硅光子学添加到其“Rosetta”Slingshot 互连中。
但在回答The Next Platform咨询时,Ayar Labs 商业运营副总裁 Terry Thorn 开玩笑说:“他们都是投资者和公司,我们正在与他们一起探索许多有趣的机会——其中大部分我们目前还不能谈论。”我们可以想象这种情况会发生,但还有许多其他方法可以实现共封装光学器件,这三家公司也都有发明自己产品的习惯。
换而言之,通过这些投资,这些芯片公司可能只是想更深入了解 Ayar Labs 正在做的事情。但正如Mark Wade在之前的采访中所说,在很多场景中会需要使用光连接。
如他所说,当Ayar Labs刚开始研究这个问题时,许多早期见解都来自高性能计算社区——你知道,国家实验室正在建造的大型机器。这些大型系统首先发现它们存在大量数据移动问题,这些问题开始成为整个系统性能的瓶颈。这就是Ayar Labs称之为“煤矿中的金丝雀”的 2010 年至 2015 年的时间段,当时的现状表明底层计算技术存在问题。
之后,随着人工智能工作流程开始出现,以及图像识别、推荐引擎等早期工作负载——但后来,特别是当转换器模型上线并开始启用新的人工智能应用程序时,我们进入了生成式人工智能时代。但关键是要意识到,构成这些人工智能计算系统骨干的计算系统看起来像高性能计算架构。
“因此,十年前在高性能计算中发生的相同数据移动挑战现在开始出现在人工智能系统中,并成为整个系统性能的瓶颈。”Mark Wade强调。
Mark Wade指出,这是一个多方面的问题。您必须让人们在功率受限的情况下将更多带宽传输到更长的距离。因此,这些系统的功率限制并不是无限的。每个级别都存在热和功率密度问题 - 芯片级、封装级、系统板级、机架级。因此,每个级别都存在功率问题。延迟是您必须更仔细检查的地方。
“如今,人们使用铜线和电气 I/O 以电气方式传输高带宽的方式,您往往会做一些事情,例如添加纠错,因为您要尝试恢复在以电气方式传输数据时发生的所有低效率和数据损坏。在光学方面,您可以以一种优雅的方式解决这个问题,从而摆脱纠错。因此,您可以获得更轻量级的纠错架构,但这会影响延迟。”Mark Wade说。
为了实现上述目标,Ayar Labs一直在丰富其产品线。
如果你看一下路线图,就会发现Ayar Labs每隔几年就会将每个芯片的带宽翻一番。他们的计划从 4 Tbps 增加到 8 Tbps,然后是 16Tbps 和 32 Tbps,这是每个芯片的带宽。Ayar Labs还下调了一些向量——每个芯片的带宽、每个封装实例化多个芯片的能力、扩大整个封装级别带宽以及可以从封装中释放的带宽基数。Ayar Labs的客户通常关注我们可以从他们的封装中释放多少带宽,以及在什么样的功率密度约束下。特别是随着人工智能系统的发展,每个封装中更高的带宽释放变得越来越重要,同时也提高了连接的基数。
目前,Ayar Labs的每个芯片有 8 个端口,每个芯片组有 8 个端口。假设每个封装有 4 个芯片组,则您的连接端口为 32 个,您可以将所有这些端口连接到不同的地方。
展望未来,Wade表示:“我们目前在实验室中与客户共同开展的工作,实际上是为了在两到三年后实现首次大规模市场部署。”
写在最后
其实光学并不是一项新技术——光纤真正进入技术领域是在 70 年代。我们开始建造海底电缆和类似的东西,最终连接互联网。光学技术是众所周知的。
但是将数据直接以光学方式从计算包中移出的需求实际上是一个相当新的现象,这与电气 I/O 问题的恶化速度有关。我们的应用程序需要更高的带宽和更好的能效——这开始打破现有的基于电气 I/O 的系统。但挑战在于,你不能只把人们使用的技术和产品用于人们可能熟悉的更标准化的解决方案,例如使用以太网的可插拔收发器。如果我在数据中心内移动 100 Gbps、400 Gbps 或 800 Gbps,那么这些已经是光学可插拔收发器了。问题是,如果你打开这些收发器并查看里面的东西,你会发现它们没有直接扩展到计算结构的特性。
因此,要实现上述目标,除了要面对尺寸、元件数量、成本结构,以及所有这些组件的组装方式外。还有功率效率、热灵敏度等问题,还有“我不能直接将收发器放入计算机封装中”的一系列问题。
“因此,我们必须从头开始发明一种具有正确底层特性的技术:密度、设备尺寸、能源效率,更重要的是,能够集成到制造工艺中,从而在 CMOS 规模下运行。我们必须掌握如何将该技术纳入封装,因为这是一种真正大规模的应用。所有这些特性在每一步都是挑战,我们公司的一部分,以及我们多年来所努力的一部分,实际上是在一步步解决这些问题。”Mark Wade表示。
面向这个市场和机会,除了Ayar Labs以外,Lightmatter、Celestial AI 、Eliyan以及国内的曦智和一大堆的处理器、晶圆厂和封装厂都在努力,为硅光子学成为计算引擎和互连之间的桥梁各出奇招。
文章来源:半导体行业观察,原文标题:《Nvidia、AMD和Intel罕见联手,投资一家光芯片公司》
风险提示及免责条款
市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
相关文章
热门文章

英伟达的竞品,真的出现了!
2024-12-07
凯里东南村镇银行被罚30万元:未严格执行风险管理及内控制度严重违反审慎经营规则
2024-11-21
一则传闻吹出三个涨停板,紧急回应:不存在!
2024-11-21
中通快递盘前涨近3% 第三季营收破百亿 同比增长17.6%
2024-11-21
佩斯科:2024年债务市场发行量将创下历史新高
2024-11-21
黄金,重大发现!尾盘直线拉升
2024-11-21
光大期货1122观点:供需驱动有限,油价或维持震荡
2024-11-22
秦书尧:将老名酒的传承和创新故事,转化为品牌力量和市场力量
2024-11-22
有话要说...